Retrieval Augmented Generation (RAG) with ChatGPT, Langchain, and Elasticsearch
Step by step guide to implement RAG using OpenAI's ChatGPT, Langchain and Elasticsearch as a vector store.

RAG with ChatGPT, Langchain & Elasticsearch
Overview
What is RAG?
RAG (Retrieval Augmented Generation) is a technique for leveraging custom data within LLM applications.
Why RAG?
RAG is a simple, cost effective way to expand (or narrow) the knowledgebase of an LLM. It allows customization of the LLM's knowledge and context without the labor of fine tuning an LLM model. RAG has also been found to significantly reduce LLM hallucinations, by providing it with "ground truth" data. With RAG, you can also achieve true "semantic search" in a much simpler way than is possible with traditional Elasticsearch queries, which are more reliant on keywords and complex query definitions.
Why Elasticsearch?
RAG is only as good as the context provided to the LLM. To get good, relevant context, you need good search results. For good search results, you guessed it, you need a great search engine.
Elasticsearch is a proven industry-leading search engine that allows for similarity search on vector embeddings, BM25 search (also known as keyword or lexical search), and hybrid search which combines the two. Hybrid search has been shown to have greater relevance than using either in isolation.
In addition to these features, Elasticsearch offers efficient filtering on different metadata fields (like location, genre, category, etc) and easy aggregations for returning facets to filter result sets on further.
Finally, if you already have an Elasticsearch cluster, you won't need to go through the pain of setting up and maintaining a separate database just for vector search.
Who is This Guide For?
This guide is for anyone interested in Generative AI, but has limited Machine Learning resources (preventing fine tuning models), wants to explore an efficient method for providing a chatGPT-like experience powered by their own data, or is just curious about Generative AI!
Guide Format & Requirements
This guide was written as an interactive notebook and assumes that you have basic software engineering skills, including familiarity with python and Jupyter notebooks. The goal is not just to read it, but to interact with it and play with it!
Feel free to open it in Google Colab, clone the github repo and run locally with Jupyter, run with VS Code, or use any other method for running a Jupyter style notebook.
Note: Google Colab is the recommended method since it creates a clean virtual environment to install our dependencies. If you're savvy with Jupyter Notebooks, please clone the repo and run your preferred way.
Lastly, you also need an OpenAI account since that is the LLM provider we will use, and some familiarty with Elasticsearch and LangChain would be nice, but not required!
How to RAG
First, we'll setup our dependencies and index data into a VectorStore.
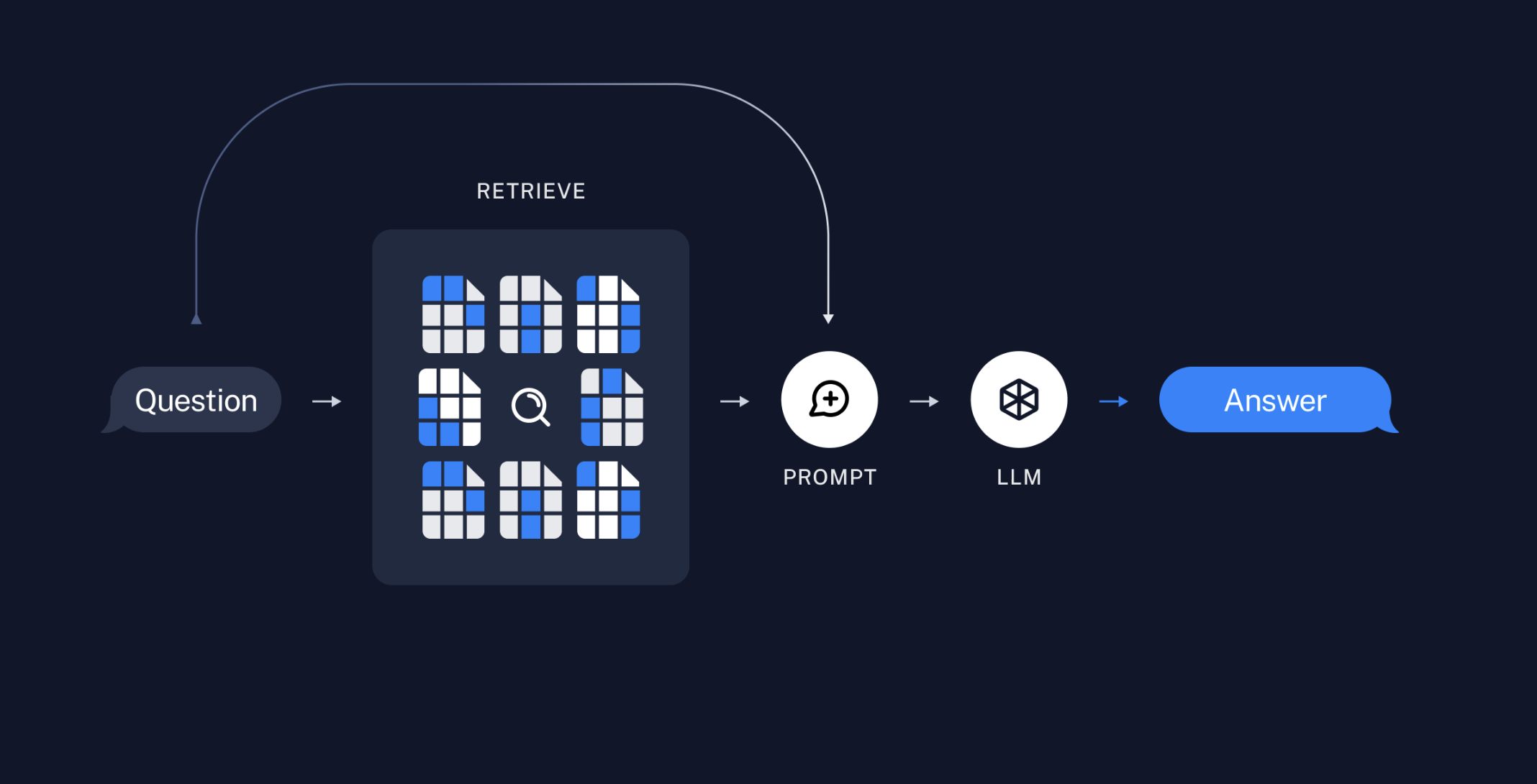
Then we'll test out our SimilaritySearch and execute a RAG chain.
Install Packages & Import Modules
%%capture
# install packages
!python3 -m pip install -qU elasticsearch==8.11.1 langchain \
sentence_transformers openai pypdf python-dotenv
# import generic modules
from IPython.display import display
from dotenv import load_dotenv
from getpass import getpass
from urllib.request import urlretrieve
import os
Setup Elasticsearch
There are 3 main options for connecting an Elasticsearch cluster to this notebook:
- download and run the Elasticsearch binary
- run a docker container
- connect to an Elastic Cloud cluster
The method you choose will depend on a couple of factors:
- where you are running this notebook
- whether you have an Elastic Cloud account
If you are running this notebook in Google Colab, it is recommended to use the binary installation or Elastic Cloud account since Docker is not supported within Google Colab.
If you are running locally (ie, a Jupyter notebook or VS Code notebook), it is recommended to use Docker or Elastic Cloud.
Barring connection/authentication or cors errors, the Elastic Cloud approach should work anywhere you run the notebook.
Enum to Track Connection Type
from enum import Enum
# let's setup a simple enum to help us keep track of our ES connection type
class ESConnection(Enum):
NONE = 0
BINARY = 1
DOCKER = 2
CLOUD = 3
es_connection = ESConnection.NONE
print(f"es_connection: {es_connection.name}")
Please skip to the follwing section that corresponds to your ES connection method (ie, run the Binary section if running in Google Colab, skip to Docker if running locally, or skip to Elastic CLoud if you have a Cloud cluster you want to use.)
ES Binary via .tar Package (Google Colab Only)
%%capture
# remove any previous elasticsearch installations, download and export es version 8.11.1
!rm -rf elasticsearch*
# !wget -q https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.11.1-linux-x86_64.tar.gz
url = "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.11.1-linux-x86_64.tar.gz"
file_name = 'es_download'
urlretrieve(url, file_name)
!tar -xzf es_download
# elasticsearch-8.11.1-linux-x86_64.tar.gz
# set up user to run ES daemon and configure cgroups
!sudo chown -R daemon:daemon elasticsearch-8.11.1/
!umount /sys/fs/cgroup
!apt install cgroup-tools
es_connection=ESConnection.BINARY
Disable security and set elasticsarch.yml parameters
# Disable security and allow anonymous users
# WARNING: this is for demo purposes only. Always use security and authentication for real world applications
with open('./elasticsearch-8.11.1/config/elasticsearch.yml', 'a') as writefile:
writefile.write("xpack.security.enabled: false\n")
writefile.write("xpack.security.authc:\n")
writefile.write(" " + "anonymous:\n")
writefile.write(" " + "username: anonymous_user\n")
writefile.write(" " + "roles: superuser\n")
writefile.write(" " + "authz_exception: true")
# if you want to verify that the elasticsearch.yml file is written to correctly, uncomment this code block
#with open('./elasticsearch-8.11.1/config/elasticsearch.yml', 'r') as readfile:
# print(readfile.read())
Start ES Daemon in Background
%%bash --bg
sudo -H -u daemon elasticsearch-8.11.1/bin/elasticsearch
It takes ES a while to get running, so be sure to wait a few seconds, or just run the manual 30 second sleep command below.
!sleep 30
Check Elasticearch Binary
We'll run a few checks to make sure Elasticsearch is up and running, and accessible
# Check if elasticsearch is running
# There should be 3 daemon elasticsearch processes and 3 root processes in the list when grepping for elasticsearch
!ps -ef | grep elastic
# curl the cluster once with the elastic superuser and default password so that we can do anonymous calls moving forward
# WARNING: do not pass user passwords like this in real life. This. is. a. demo.
!curl -u elastic:password -H 'Content-Type: application/json' -XGET http://localhost:9200/?pretty=true
Docker (Local Notebook Only)
Docker doesn't work in Google Colab. But if you're running this notebook locally, you can spin up a docker container to connect to. Checkout Elasticsearch's guide for setting up a single container, or multi-node cluster with docker-compose.
The docker-compose approach is nice because you almost never have a single node cluster, and you get kibana with it as well. One big thing to note is that the docker-compose file sets up ssl and security (username/password) by default, which our notebook is not configured to handle, so you'll want to set the security values to false and comment out the ssl stuff. Here's an example of what the docker-compose file might look like.
Our example .env file includes environment variables for the docker-compose file. Assuming the .env_example file has been renamed to .env, you can run docker-compose up in a local terminal, and your notebook should be able to connect.
NOTE: our notebook assumes url of
http://localhost:9200when running Elasticsearch on docker.
# uncomment and run this block to use Docker connection
#es_connection=ESConnection.DOCKER
Elastic Cloud
Many organizations may already have an Elastic Cloud cluster to connect to. Or maybe you have a free trial. In either case, we can simply pass in the cloud id and api key to create a client.
Please refer to the Elasticsearch documentation for retreiving this information. We will pass these values in securely when we setup environment variables in our next step.
# uncomment and run this block to use Elastic Cloud connection
#es_connection=ESConnection.CLOUD
Setup Environment Variables
To integrate our RAG app with OpenAI and Elasticsearch, we need to pass some sensitive data, like api keys and passwords. We'll use python's getpass package to input the sensitve info, and store it in a .env file that we can then use in our code.
It's a bit of a roundabout approach, but better than pasting senstive data directly into the code. You can skip to the load_dotenv() function if running locally and have your own .env file at the root directory, next to the ipynb file.
# create .env file
!touch .env
with open('.env', 'a') as envFile:
# write openai api key
envFile.write("OPENAI_API_KEY=" + getpass(prompt="enter your openai api key ") + "\n")
# if running es binary or docker, add the es_url
if es_connection == ESConnection.BINARY or es_connection == ESConnection.DOCKER:
envFile.write("ELASTICSEARCH_URL=http://localhost:9200" + "\n")
# if running es cloud, enter cloud id and api key
elif es_connection == ESConnection.CLOUD:
envFile.write("ELASTIC_CLOUD_ID=" + getpass(prompt="enter your ES cloud id ")+ "\n")
envFile.write("ELASTIC_API_KEY=" + getpass(prompt="enter your ES cloud api key "))
# uncomment this section if you need to double check the .env file
# with open('.env', 'r') as readfile:
# print(readfile.read())
# Load variables from .env file
load_dotenv('.env')
# Set local variables
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
ELASTIC_CLOUD_ID = os.getenv("ELASTIC_CLOUD_ID")
ELASTIC_API_KEY = os.getenv("ELASTIC_API_KEY")
ELASTICSEARCH_URL = os.getenv("ELASTICSEARCH_URL")
Final Elasticsearch Check
Instantiate Elasticsearch python client based on installation type and double check connection.
from elasticsearch import Elasticsearch
# determine what connection data to pass to the client init
if ELASTICSEARCH_URL:
elasticsearch_client = Elasticsearch(
hosts=[ELASTICSEARCH_URL],
)
elif ELASTIC_CLOUD_ID:
elasticsearch_client = Elasticsearch(
cloud_id=ELASTIC_CLOUD_ID, api_key=ELASTIC_API_KEY
)
else:
raise ValueError(
"Please provide either ELASTICSEARCH_URL or ELASTIC_CLOUD_ID and ELASTIC_API_KEY"
)
print(elasticsearch_client.info())
Load Data
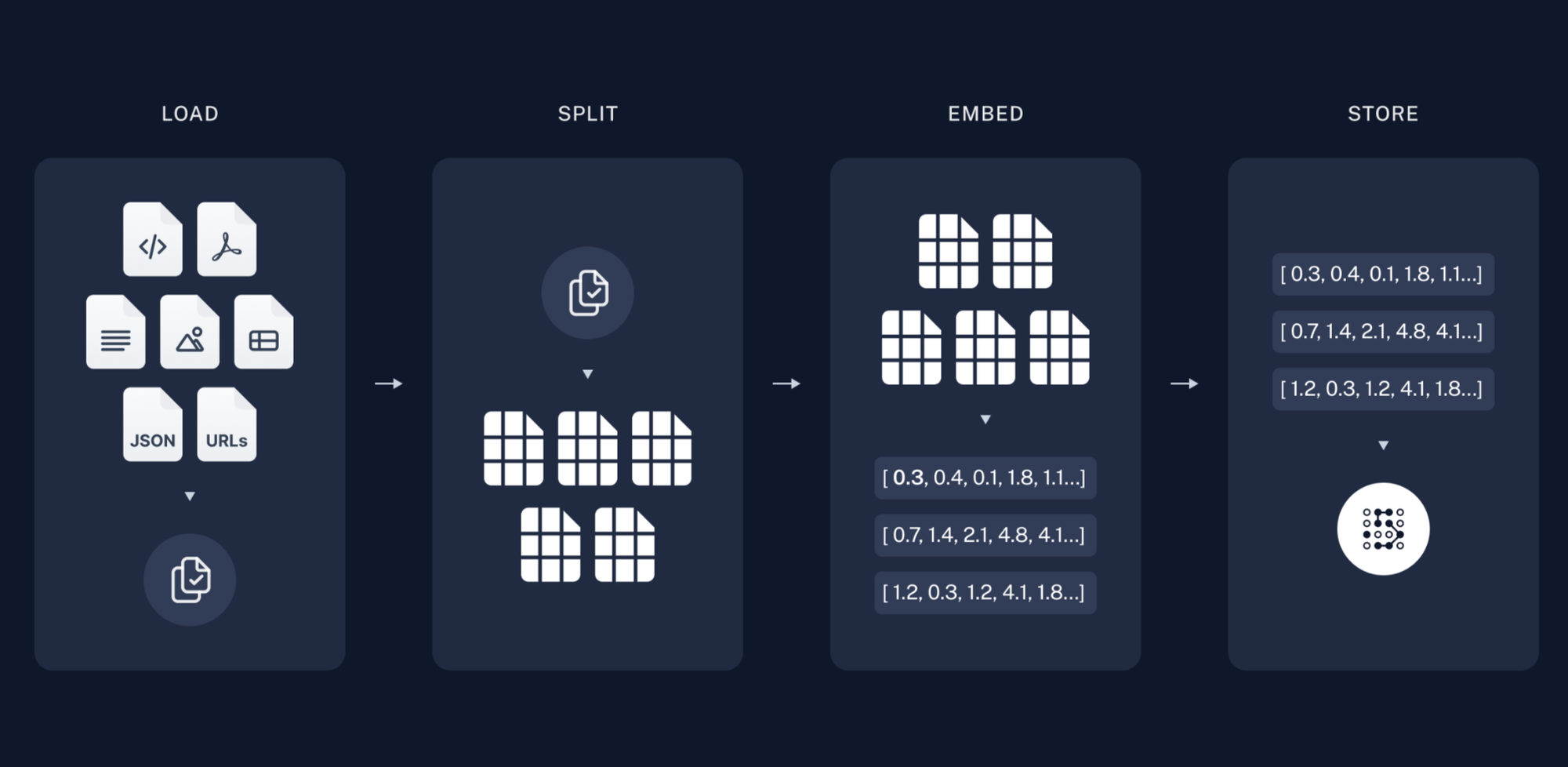
Our dataset is a pdf of the United States Code Title 3 - The President, available from The Office of Law Revision Counsel website. We use langchain's PyPDFLoader to load the pdf and split into pages.
Langchain provides many different types of document loaders for a myriad of data sources. Additionally, sometimes the documents need to be parsed and split into smaller chunks for ingestion. This can be done using document transformers.
At their core, document loaders translate source data into langchain Document objects, which consist of page_content, and optional metadata.
Get the PDF and Split into Pages
from langchain.document_loaders import PyPDFLoader
# get the us code pdf on the president and unzip it
from urllib.request import urlretrieve
url = "https://uscode.house.gov/download/releasepoints/us/pl/118/22u1/pdf_usc03@118-22u1.zip"
file_name = "president.pdf.zip"
urlretrieve(url, file_name)
!unzip president.pdf.zip
# now load the pdf as text and break into pages
loader = PyPDFLoader("usc03@118-22.pdf")
pages = loader.load_and_split()
Next, we instantiate a langchain VectorStore of the ElasticsearchStore type.
Instantiate ElasticsearchStore
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import ElasticsearchStore
# set our embedding model
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# instantiate vectorstore from documents
esVectorStore = ElasticsearchStore.from_documents(
pages,
es_connection=elasticsearch_client,
index_name="the-president",
embedding=embeddings
)
# verify the ElasticsearchStore was created
esVectorStore
We're using the from_documents() function, which creates a new index and ingests our documents automatically. It accepts our list of documents (pages), embedding function (in our case, an SBERT sentence transformer available from Hugging Face), and Elasticsearch client and index. You can also pass in Elasticsearch url/credentials if you haven't already instantiated an Elasticsearch client.
Our new index will consist of documents with text and embedding fields. If we had added metadata to our documents when loading our pdf, it would also index this information. (Metadata can be information like the document name, page number, date, etc. and is useful for filtering or aggregating on our searches.)
Alternatively, if you have an existing Elasticsearch index you want to use, or want to manage your index separately from the built in langchain from_documents function, you can instantiate the Elasticsearchstore by iteslef:
esVectorStore = ElasticsearchStore(
es_url="http://localhost:9200",
index_name="test_index",
embedding=embedding
)
Though we're using an SBERT sentence transformer, additional embedding models are available. Langchain integrates with many different embedding providers, including OpenAI, SpaCy, Elasticsearch and more.
Test Similarity Search
Next, we test our similarity_search function to ensure we pass appropriate context to our langchain prompt.
Helper Function
# helper function
def showResults(results):
print("Total results: ", len(results))
for i in range(len(results)):
print(results[i])
showResults() is a just a helper function to help display our results later.
Similarty Search
query = "who succeeds the president"
result = esVectorStore.similarity_search(query=query)
showResults(result)
We use the default similarity_search() function from langchain. By default it will use ApproxRetrievalStrategy. This uses the Elasticsearch Approximate kNN search using the embedding model we specified in the VectorStore, and the HNSW algorithm and cosine distance.
There are other retieval strategies, distance strategies, and model options to choose from when setting up the ElasticsearchStore. The langchain documentation has helpful examples including using custom Elasticsearch embedding models, using Sparse Vectors with ELSER , and using a completely custom Elasticsearch query (in the example, they replace the similarity query with a basic BM25 match query.)
One thing that differentiates Elasticsearch from other vector datastores is the ability to do hybrid search, which combines vector similarity search with more traditional BM25 and has been shown to increase relevance.
For more information about the ElasticsearchStore class, checkout the api documentation . For an even further in-depth look at what goes on under the hood, reference the Elasticsearch vector store github repo.
Executing RAG
Finally, we setup and execute our RAG chain.
When prompted below, try asking questions about the President:
- What are the president's duties?
- How often is the president elected?
- Who succeeds the president?
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
retriever = esVectorStore.as_retriever(search_kwargs={"k": 3})
template = """Answer the question with the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI(openai_api_key=OPENAI_API_KEY)
| StrOutputParser()
)
q = input("Question: ") or "What is the electoral college?"
print("\n")
reply = chain.invoke(q)
display("Answer: " + reply)
Breakdown the Chain
It's not a ton of code, but there's a lot going on here, so let's break it down.
Retriever
retriever = esVectorStore.as_retriever(search_kwargs={"k": 3})
First we set up something called a Retriever. This is a LangChain component to return documents to pass as context to our prompt. It doesn't have to be based on a VectorStore, but in our case, that's exactly what it is -- our ElasticsearchStore is what we use to search and retrieve relevant documents.
You don't have to use a retriever. LangChain's prompt template supports something called RunnableLambda's, which are just custom functions you can pass to the prompt.
Prompt
template = """Answer the question with the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
This is of course the prompt we will pass to the LLM. We set up a template which sets up our context and passes through the inputted question.
Chain
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI(openai_api_key=OPENAI_API_KEY)
| StrOutputParser()
)
The chain is the core of what LangChain does (hence the name, right?). They provide a simple syntax language (LangChain Expression Language aka LCEL) that uses pipes akin to unix pipes. We set our variables here to pass context and question to our prompt. We specify the LLM model to use (ChatOpenAI), and lastly we specify an output parser to make sure our output is a string.
Invoke
q = input("Question: ") or "What is the electoral college?"
print("\n")
reply = chain.invoke(q)
display("Answer: " + reply)
The last step here is to prompt for a user question, which we then pass to the chain.invoke() function. This of course, runs the chain which triggers an Elasticsearch query with the question as input, and then returns the result as context in our LLM prompt. The LLM prompt also uses the original question.
The result is that our question is answerd by the LLM based on the data retreived by Elasticsearch.
Go Deeper
This guide has walked through the basic steps of setting up RAG by using LangChain to load data from a pdf, create a VectorStore in Elsticsearch, query Elasticsearch for relevant data, and pass that data to ChatGPT as context in a prompt.
Along the way we mentioned different ways to customize this application including using an existing Elasticsearch index, customizing the Elasticsearch query, using custom language models for embedding, and that's just the start!
If you want to learn more, the best way is to experiment. Maybe try loading a different data type (you can retrieve the same US Code data as html for example), or a different data source (gutenberg.org is a free online source where you can access public domain books, for example.)
Play with different Elasticsearch retrieval and distance strategies. How does BM25 compare to semantic similarity and hybrid search?
Maybe try a custom LLM, like Dolly, or Llama.
Here's a crazy suggesion -- try a different Vector Store. Opensearch is a great Lucene-based alternative to Elasticsearch, but you could even try a different open-source vector database, like Chroma. This Linkedin post offers a nice feature comparison of different vector stores.
Closing
Of course, reach out to us at Gigasearch if you have any questions. We'd be happy to talk about RAG, how you could implement generative AI in your business, or any general Elasticsearch/Opensearch questions you may have.