Reranking Opensearch Results with Cohere
Discover how integrating Cohere's Rerank model with Opensearch can skyrocket your search relevancy—outperforming even advanced semantic search techniques.

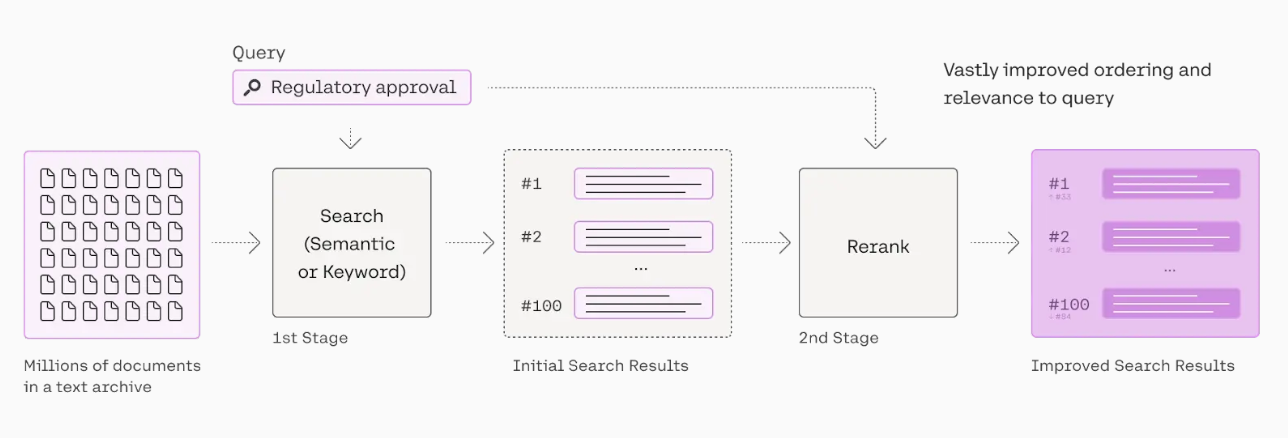
Imagine boosting your lexical (BM25) search results without relying on LLMs or managing complex vector embedding pipelines. What if these improved results could even outperform semantic search using state-of-the-art SentenceTransformers vector embeddings*? Intrigued? Read on!
TL;DR
You can improve the relevancy of your search results by integrating Cohere’s powerful Rerank model directly into your Opensearch or Elasticsearch search pipeline – no machine learning experience required. What’s more, you can do it in as little as 10 minutes. This guide will walk you through the process of setting this up with Opensearch and Cohere, including a Colab notebook, and retrieval performance benchmarks.
Prerequisites
You’ll need:
- A Cohere api key
- Some familiarity with Elasticsearch or Opensearch
- Python familiarity helps, but not required
- Remote access to your Opensearch cluster (or just set up a new one with test data).
Feel free to copy the code to your own IDE or notebook environment, but it’ll definitely be quicker and easier to run through the full example in our google colab notebook. From there, it should be pretty straightforward to port over to your own environment.
Basic Steps
- Register a Cohere Rerank model
- Configure a reranking (search) pipeline
- Use the search pipeline
You can actually see these steps in the official Opensearch documentation here, but we’ve gone ahead and taken their examples a step further by laying it all out in our example notebook.
Register a Cohere Rerank Model
First, we create the ML Connector. We’ll set up a basic http request in python, specifying the ml connector /_create endpoint, and a json body with our Cohere rerank model information, like name, api key, and the request endpoint and body to send to the rerank api:
import requests
url = "http://localhost:9200/_plugins/_ml/connectors/_create"
headers = {
'Content-Type': 'application/json'
}
data = {
"name": "cohere-rerank",
"description": "The connector to Cohere reranker model",
"version": "1",
"protocol": "http",
"credential": {
"cohere_key": cohere_api_key
},
"parameters": {
"model": "rerank-english-v2.0"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://api.cohere.ai/v1/rerank",
"headers": {
"Authorization": "Bearer ${credential.cohere_key}"
},
"request_body": "{ \"documents\": ${parameters.documents}, \"query\": \"${parameters.query}\", \"model\": \"${parameters.model}\", \"top_n\": ${parameters.top_n} }",
"pre_process_function": "connector.pre_process.cohere.rerank",
"post_process_function": "connector.post_process.cohere.rerank"
}
]
}
response = requests.post(url, headers=headers, json=data)
connector_id = response.json()['connector_id']We use an http request here because registering an external ML model doesn’t seem to be supported in the python ml client at this time.
Next, we register and deploy our model:
url = "http://localhost:9200/_plugins/_ml/models/_register?deploy=true"
headers = {
'Content-Type': 'application/json'
}
data = {
"name": "cohere rerank model",
"function_name": "remote",
"description": "test rerank model",
"connector_id": connector_id
}
response = requests.post(url, headers=headers, json=data)
task_id = response.json()['task_id']
model_id = response.json()['model_id']Finally, we can test our model with the /_predict endpoint:
import json
url = "http://localhost:9200/_plugins/_ml/models/" + model_id + "/_predict"
headers = {
'Content-Type': 'application/json'
}
data = {
"parameters": {
"query": "Who is the main character of Star Wars?",
"documents": [
"Jar-Jar Binks is a comical, possibly secret sith character in Star Wars.",
"Darth Vader, aka Anakin Skywalker is the main antagonist of the original Star Wars trilogy.",
"Luke Skywalker is the main protagonist of the original Star Wars trilogy.",
"Emperor Palpatine is arguably the main antogonist as he is the main sith lord."
],
"top_n": 4
}
}
response = requests.post(url, headers=headers, json=data)Configure a Reranking (Search) Pipeline
We need to tell the opensearch rerank query that we have a special reranking process for it to use. We create a search_pipeline with our cohere model_id and body field parameters (title and txt.)
url = "http://localhost:9200/_search/pipeline/rerank_pipeline_cohere"
headers = {
'Content-Type': 'application/json'
}
data = {
"description": "Pipeline for reranking with Cohere Rerank model",
"response_processors": [
{
"rerank": {
"ml_opensearch": {
"model_id": model_id
},
"context": {
"document_fields": ["title", "txt"],
}
}
}
]
}
response = requests.put(url, headers=headers, json=data)Use the Search Pipeline
Now, when we submit a search request that we want reranked by Cohere, we’ll need to specify the search_pipeline we made for Cohere reranking. This can be done on the individual search request, or a default search_pipeline can be set for an index.
query_text = 'A total of 1,000 people in the UK are asymptomatic carriers of vCJD infection.'
res = client.search(
index="scifact",
search_pipeline="rerank_pipeline_cohere",
body={
"query": {
"multi_match": {
"query": query_text,
"type": "best_fields",
"fields": [
"title",
"txt"
],
"tie_breaker": 0.5
}
},
"size": 10,
"ext": {
"rerank": {
"query_context": {
"query_text": query_text
}
}
}
}
)Opensearch with Cohere Rerank Results
{
"id": "13734012",
"score": 0.9920002,
"title": "Prevalent abnormal prion protein in human appendixes after bovine spongiform encephalopathy epizootic: large scale survey",
"text": "OBJECTIVES To carry out a further survey of archived appendix samples to understand..."
},
{
"id": "18617259",
"score": 0.9896318,
"title": "Research Letters",
"text": "We report a case of preclinical variant Creutzfeldt-Jakob disease..."
},
{
"id": "11349166",
"score": 0.95447797,
"title": "Lack of evidence of transfusion transmission of Creutzfeldt-Jakob disease in a US surveillance study.",
"text": "BACKGROUND Since 2004, several reported transfusion transmissions of variant Creutzfeldt-Jakob disease..."
}And finally, we can compare with a non-reranked search:
res = client.search(
index="scifact",
body={
"query": {
"multi_match": {
"query": query_text,
"type": "best_fields",
"fields": [
"title",
"txt"
],
"tie_breaker": 0.5
}
},
"size": 10
}
)Regular Opensearch BM25 Results
{
"id": "18617259",
"score": 22.933357,
"title": "Research Letters",
"text": "We report a case of preclinical variant Creutzfeldt-Jakob disease..."
},
{
"id": "13734012",
"score": 18.917074,
"title": "Prevalent abnormal prion protein in human appendixes after bovine spongiform encephalopathy epizootic: large scale survey",
"text": "OBJECTIVES To carry out a further survey of archived appendix samples..."
},
{
"id": "15648443",
"score": 16.957115,
"title": "Long-term effect of aspirin on cancer risk in carriers of hereditary colorectal cancer: an analysis from the CAPP2 randomised controlled trial",
"text": "BACKGROUND Observational studies report reduced colorectal cancer in regular aspirin..."
}Our very scientific example query comes directly from the scifi dataset: A total of 1,000 people in the UK are asymptomatic carriers of vCJD infection. The expected result is the document with id 13734012 and title Prevalent abnormal prion protein in human appendixes after bovine spongiform encephalopathy epizootic: large scale survey.
This example shows how our document ranked second in the standard search but first in the reranked results, showcasing an improvement in relevance. While this single instance is anecdotal, we conducted a more comprehensive analysis using Benchmarking-IR (BEIR), an industry standard for benchmarking information retrieval. We calculated several relevance metrics across all queries in the sci-fi dataset, revealing consistent improvements across all scores, as illustrated below.
Performance Metrics
Relevance (Normalized Discounted Cumulative Gain)
| Relevance | SBERT | TAS-B | BM25 + CE | BM25 | BM25 + Cohere |
|---|---|---|---|---|---|
| NDCG@1 | 0.42333 | 0.44667 | 0.5733 | 0.57667 | 0.62667 |
| NDCG@3 | 0.48416 | 0.50432 | 0.6314 | 0.63658 | 0.69593 |
| NDCG@5 | 0.48416 | 0.52853 | 0.652 | 0.66524 | 0.7141 |
| NDCG@10 | 0.53789 | 0.55485 | 0.672 | 0.69064 | 0.73495 |
| NDCG@100 | 0.57592 | 0.58717 | 0.678 | 0.71337 | 0.75241 |
- SBERT refers to an exact k-nn match using the sbert
msmarco-distilbert-base-v3model. - TAS-B is exact match with sbert
msmarco-distilbert-base-tas-bmodel. - BM25 + CE is the base bm25 results reranked with the
ms-marco-electra-baseSBERT cross-encoder. - BM25 is the base performance of a
multi_matchquery in Opensearch. - Finally, BM25 + Cohere is the performance of Opensearch when using the Cohere rerank pipeline.
Latency
| Latency | BM25 | BM25 + Cohere | BM25 + CE CPU |
|---|---|---|---|
| Average | 14.26ms | 214.03ms | 8745.06ms |
| P50 | 13.06ms | 150.35ms | 8527.61ms |
| P90 | 19.73ms | 406.88ms | 12713.91ms |
| P99 | 31.51ms | 870.71ms | 15520.40ms |
To test latency, we looped over the 300 queries in the scifi dataset and measured how long each request took with the corresponding retrieval method (BM25, BM25 + Cohere, BM25 + CE).
As you can see, relevance (as measured by nDCG) is improved at the cost of some increased latency. This is common when using cross-encoder models for reranking. However, the Cohere reranking pipeline performed significantly better than our test with self-hosting a cross-encoder model, where latency increased substantially without proper processing power.
In our self-hosting tests, we ran the sbert cross-encoder on Google Colab’s CPU and you can see the latency reached unacceptable levels. To improve the performance, the production environment would likely need many high performance CPUs or better yet, GPUs.
It's also worth noting that at the time of this blog's release Cohere has released their Rerank 3 Nimble model, which claims to be 3x faster than Rerank 3. However, it is only available for on AWS SageMaker and on-premise deployments.
Conclusion
There you have it. If you were following along, you were able to set up an Opensearch integration with the Cohere Rerank api in a very short amount of time, increasing the relevance of your search results with little effort! As always, if you’d like to talk more about search relevance, reranking and other ai search solutions, reach out to Gigasearch!
*According to BEIR Heterogenous Benchmarking for Information Retrieval, cross-encoders outperform bi-encoder semantic search approaches for relevance.