Elasticsearch Hot-Warm Architecture


Your Elasticsearch cluster is growing rapidly. So rapidly, in fact, that you can no longer retain the amount of data you want without paying an obscene AWS or GCP bill. Most of your searches might be for data from the last couple days, but you have a long tail of searches for data up to a month old. What if you could increase retention without breaking the bank?
What is Hot-Warm?
In a hot-warm architecture, you have two node types: hot (machines with fast SSDs), and warm (machines with slow spinning disks, cheaper SSDs, or EBS). Indices that are currently being indexed into and/or have high search volume are placed on the hot nodes, while indices that have relatively lower search volume and/or no indexing go on warm nodes. This makes a lot of sense for time-based use cases like logging and metrics, which have a heavy bias towards more recent data. Hot-warm is also an efficient way to keep shards below the recommended 50gb size, since you can rollover to a new index after hitting a certain index size. Searches on warm data also won't compete with indexing, since all indexing is done on hot nodes.
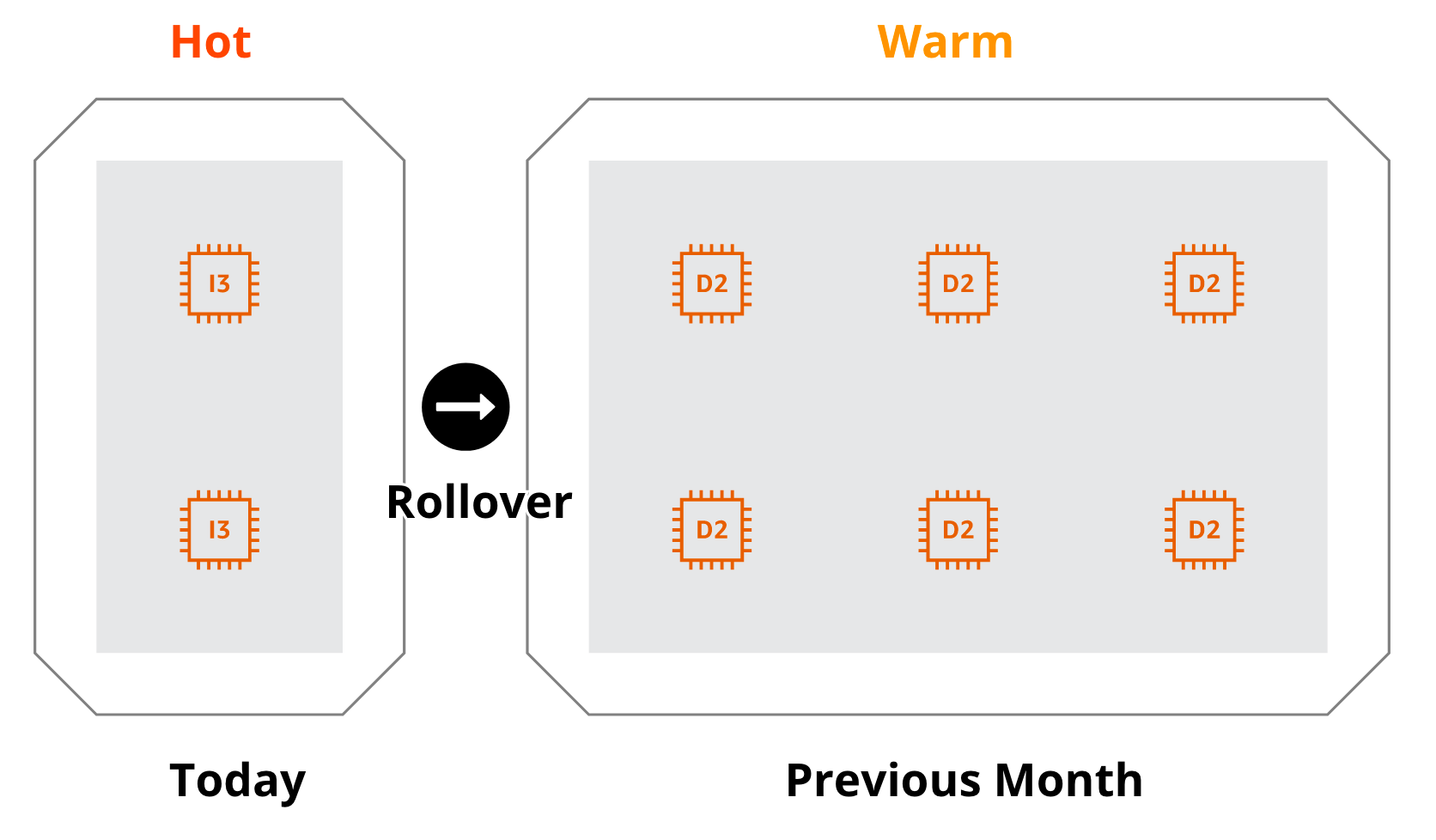
In the diagram above, today's indices are stored on "hot" i/o optimized I3 nodes, while all remaining indices from the rest of the month are stored on "warm" D2 nodes with cheap spinning disks. The node types you decide on will be heavily dependent on your use case and budget. You can also configure rollover based on number of documents or index size, which may be preferable depending on your goals.
Setup
If you're running Elasticsearch self-hosted, you'll need to get your hands dirty. Set node.attr.box_type: hot in elasticsearch.yml on all your hot nodes, and node.attr.box_type: warm on warm nodes. Note that you'll need to restart the nodes for this to take effect. Then you'll need to configure newly created indices to route shards only to these hot nodes. You can do this by updating your index template:
PUT _template/logs-template {
"index_patterns": [
"logs-*"
],
"settings": {
"index.routing.allocation.require.box_type": "hot"
}
}
You can then use Curator to automatically move indices to warm nodes after 1 or more days. Typically Curator is scheduled to run on one node connected to your Elasticsearch cluster via crontab.
The lifecycle of indices can also be managed using Index Lifecycle Management (ILM). ILM makes the operation of a hot-warm cluster relatively painless, since you can configure all aspects of managing the hot-warm cluster via the Kibana UI. Note that this is an x-pack feature, so you'll need to have at least a basic Elastic license on your nodes. ILM also comes built into Elastic Cloud.
Hot-warm on AWS Elasticsearch Service
An interesting alternative to warm nodes is the new UltraWarm tier on AWS Elasticsearch Service. The underlying storage for UltraWarm is S3, which is over 5x cheaper than EBS. You also don’t need replicas due to the very high availability guarantees of S3. We at Gigasearch have not yet run this in production, so we can't vouch for the performance characteristics. AWS ESS did not previously have any support for hot-warm, and UltraWarm is the only way to achieve hot-warm on AWS ESS currently.
Caveats
A potential issue with this is lots of shard movement from hot to warm nodes triggered at midnight UTC every day. All shards that are currently on hot nodes will need to move to warm nodes. This, paired with high put-mappings load on the master due to new indices being created, can create problems for very large clusters. The master node can get overwhelmed with pending tasks, bringing down the cluster. This is usually only a concern for very large clusters with large mappings, hundreds of indices, and thousands of shards.
Also, by design, performance will be worse for queries that users initiate on data in warm nodes. Hot/warm is mostly a cost optimization, not a performance optimization. If you want good performance for all queries and budget is less of an issue, you can consider i3en.2xl nodes for all data nodes instead, since you get over 2x the SSD capacity for up to 50% less.
Elasticeasrch with hot-warm architecture can, if set up well, deliver a cost-effective solution to retaining large amounts of data within your cluster. It is crucial to consider your use-case before embarking on this journey. Gigasearch is a team of Elasticsearch consultants and engineers with experience deploying petabyte-scale clusters. Contact us today.